Lecture 11
Text compression
What is compression?
- Idea: We want to reduce the size of some data. This allows faster transfer across networks, smaller footprint to store, …
- Why: Because data is exploding!!11!
When is compression used?
- Very often!
- Files: zip, gzip, bzip2, xz, …
- File systems: NTFS, ZFS, …
- Images: gif, jpeg, …
- Sound: mp3, …
- Videos: mpeg, divx, …
- And so on!
Basic idea
- We are given a text
M - We encode
Mto generate a (hopefully) compressed representation - Given , we can decode it to get back
- Lossless compression:
- Lossy otherwise
- Compression ratio: bits in C(M) / bits in M
- the smaller the value the better
Lossy vs Lossless
Lossy compression
- Common for images, sound, video
- Often not noticed by consumers
- Typical ratio: 10% or less!
Lossless compression
- Text, source code, executables
- codepressing source code repository, etc.
- Typical ratios: 50%?
Simple Ideas and Intuition
- Look for redundancy
- look for patterns to exploit
- Code things that occur often with fewer bits
GTCACCCCCCCCCGTCCCCCCCCCCCCC
CCCCCCCCCCCCCCCCCCCCCCCCCTGG
- If I see a “C”, I look forwards until I see something else, and then I replace the C sequence with a count
= GTC1AC9GTC41TGG
Ratio: Around 40% of the original!
Run-Length-Encoding (RLE)
- The more general idea here is called Run Length Encoding (RLE).
- List the character and then the run length as a pair:
- G1T1C1A1C9 means (G, 1) (T, 1) (C, 1) (A, 1) (C, 9)
- Works well for long runs of repeated data
Smarter DNA coding
- Alphabet size is 4, so we can represent each base (A, G, T, C) with just two bits!
- A = 00, G = 01, T = 10, C = 11
- Uses 112 bits (ignoring padding)
- That’s about 25% of the original!
- Known as a “fixed length” code
- This would work well if they were all the same frequency
- Intuition: C turns up a lot… Shouldn’t we give C a shorter code word?
- Known as a “variable length” coding
- Uses a different number of bits to encode each character
Variable length codes
- Ambiguity problems
- G = 10, A = 0, C = 1, T = 11
- Given a sequence of bits: 1100
- Is it TAA? CCAA? CGA? …
- Codewords must be prefix free
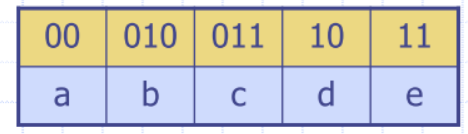
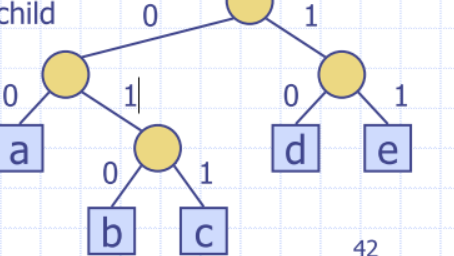
Prefix Codes
-
We can compress a string X into a smaller string Y by using a prefix code for the characters of X
-
Mapping each character of an alphabet to a binary code-word
- no code-word is the prefix of another code-word
- Proof: No internal node is used as an endpoint
-
Encoding trie represents a prefix code
- each external node stores a character
- code word of a character is given by the path from the root to the external node storing the character
- 0 for a left child and 1 for a right child, e.g.
| Codex | Graph |
|---|---|
 |
 |
Encoding Tree Optimisation
-
Given a text string X, find a prefix code for the characters of X that yields the smallest possible encoding for X
- frequent characters should have short code-words
- rare characters should have long code-words
-
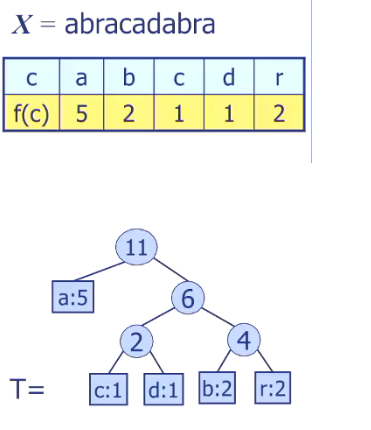
X = abracadabra
-
encodes X into 29 bits
- 010 11 011 010 00 010 10 010 11 011 010
-
encodes X into 23 bits
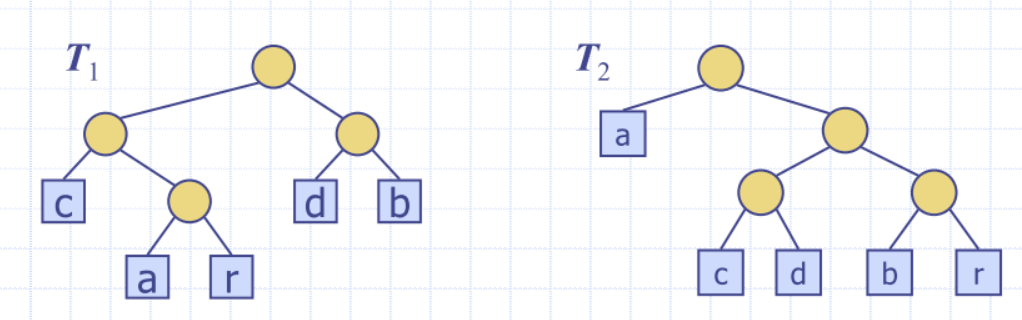
Huffman Coding
- We want to find an optimal prefix-free coding scheme
- Given a string X, constructs a prefix code that minimises the size of the encoding of X
- Given: a set of positive weights
- Compute: a set of corresponding codeword lengths, , such that:
- ensures we get a viable code (can't set = 0)
- minimises the overall cost of storing the input
Algorithm Huffman(X):
Input: string X of length n
Output:optimal encoding tree for X
Compute frequency f(c) of each character c of X
PQ <- new empty Priority Queue
for each character c in alphabet of X do
T <- single node binary tree storing c
PQ.insert(f(c), T)
while PQ.size() > 1 do
(f1, T1) = PQ.removeMin()
(f2, T2) = PQ.removeMin()
T <- a new binary tree T with left subtree T1 and right subtree T2
PQ.insert(f1+ f2, T)
(f, T) = PQ.removeMin()
return T
Analysis of Huffman’s Algorithm
Assuming that
n: size of Xd: number of distinct characters of X- PQ is implemented using a heap
- Runs in time
Real Huffman coding
In practice, we don’t actually care about the codewords in the first instance – we actually want to compute the set of codeword lengths (how many bits to assign to each codeword)
Huffman's example
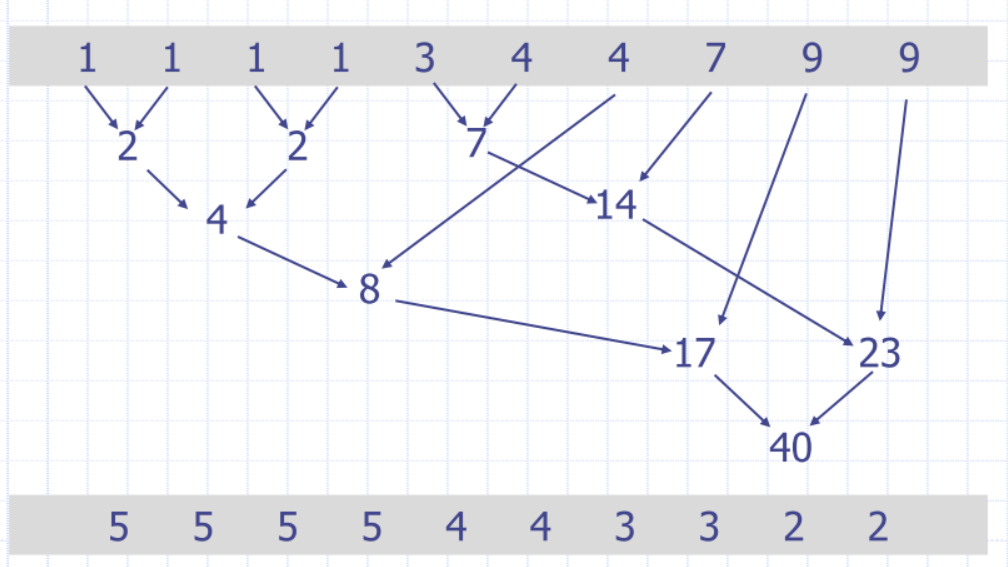
Assign codewords by the branch direction of the tree: “If we go left, assign 0, else assign 1” But we can do better (where better does not mean a better code, but more beautiful, elegant, and less overhead when transmitting the codebook)

Canonical codes
- chop off the lest significant bit (LSB)
Canonical codes - tree shape
Because it means we can minimize the amount of information we provide to the decoder. Suppose we pass the symbols to the decoder in lexicographical order. If we sort the codewords first by their length and then lexicographically, all we need to provide the decoder is the list of codeword lengths!
Sort them within their bit length buckets
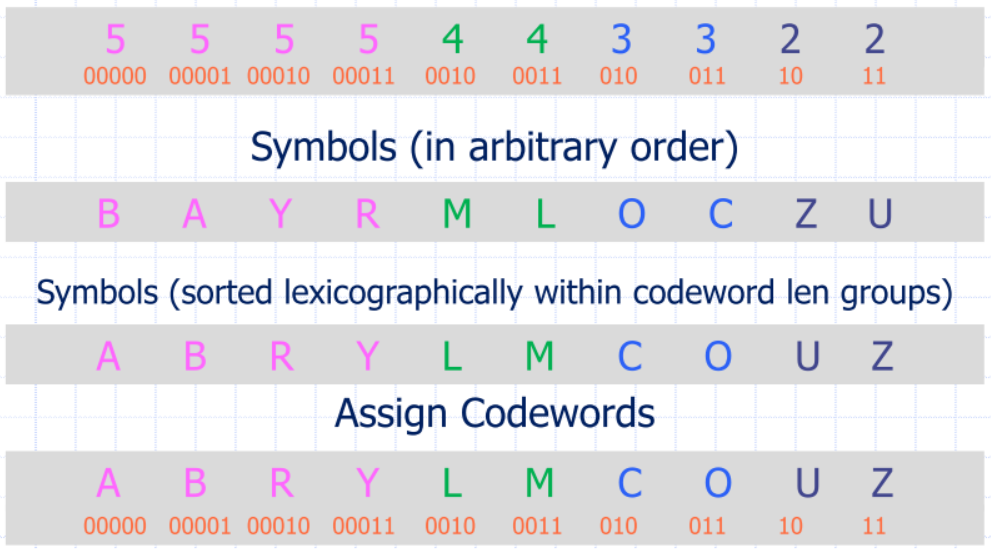
How to transmit the codebook?
- Transmit symbols in decreasing order of bitlength, recording the number of symbols in each bitlength group
- IMPORTANT
- Codebook = (4, 2, 2, 2, 0) (A, B, R, Y, L, M, C, O, U, Z)
- know the most simple codeword you can come up with for a length of 5 bitlength group (it is 00000)
- 0: “zero codewords of length 1”
- 2: “two codewords of length 2”
Decoder
- Step 1. Recover the code/symbol mapping.
- Step 2. Apply it to the bit sequence.
Compression and coding
- Compression is the process of:
- Building a probability model over the input
- Applying that probability model to the data
Lempel-Ziv Schemes
Statistical Methods
Static Models
- Use the same model for all inputs
- ASCII, Morse code, …
Dynamic Models
- Generate the statistical model based on the input
- Huffman codes
Adaptive Models
- Update the model as you read through the input
- Lempel-Ziv
Lempel-Ziv Compression
Basic idea: Use a dictionary to determine if you have seen something before. If so, don’t output the “thing”, just output its index in the dictionary!
-
dictionary is the context of stuff you've seen before
-
Setup: Want to encode some source
S -
LZ77 uses a sliding “context” window to serve as the dictionary (the previous W chars)
-
At position p, search for the longest match
S[p..]with respect toP[p-W … p-1]and code the match if found -
S = “HELLO YELLOW”, W = 5
-
If we were looking at p=7 (the “E” in “YELLOW”)
LZ77 example
- What I 'mismatched' was an A


LZ77 decoding example
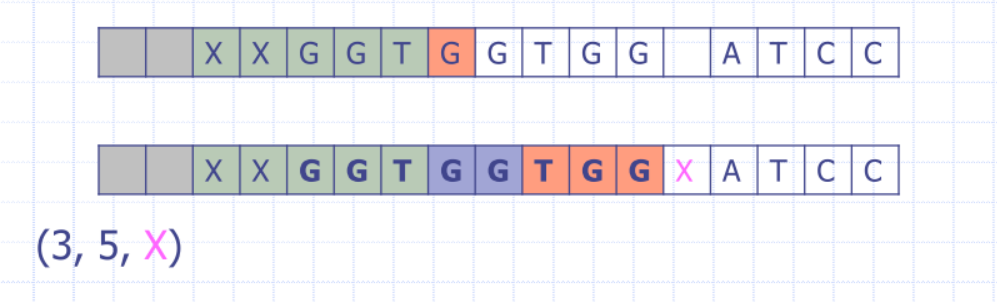
- The algorithm we observed is a simplified version of LZ77
- The true LZ77 employs a lookahead buffer that allows matches to overflow into the current pattern! At decoding time you will see this: (3, 5, X) How can I decode 5 elements when I only go back by an offset of 3?
What about Huffman?
- We can use the output of LZ as input to
Huffman!
- In particular, we can use LZ to replace the input text with back pointers as we saw previously
- We then can use Huffman coding on the output stream provided by LZ to better handle those symbols (often a different Huffman code for each part of the stream)
- This is know as DEFLATE (or FLATE) and is used in PKZIP
LZ* challenges
- LZ compression offers a number of
interesting algorithmic challenges
- How to match patterns in the window?
- How big should the dictionary/window be?
- How can we better handle inefficiencies where the encoded segment is larger than its original representation?
- How many bits to use for each part of the triple?
- And so on…
- In practice, (zlib for example), LZ77 uses W=32K
Variable Byte
130 would usually be:
00000000000000000000000010000010
But now we can represent it as:
10000001 00000010
The leftmost 1 says “you need to read
another byte” (continuation bit)