Chapter 12.1 Why study Sorting algorithms?
Given a collection, the goal is to rearrange the elements so that they are ordered from smallest to largest
- In python, the natural order of object is typically defined with the operator, having the following properties
- Sorting is amongst the most important of computing problems
- merge sort, quick-sort, bucket-srt, and radix sort
12.2 Merge-Sort
Divide and Conquer
The first two algorithms in this chapter use recursion in an algorithmic design patterns called divide and conquer. This pattern consists of the following three steps:
- Divide: If the input size is smaller than a certain threshold, solve the problem directly using a straightforward method and return the solution so obtained. Otherwise, divide the input data into two or more disjoint subsets
- Conquer: Recursively solve the subproblems associated with the subsets
- Combine: Take the solutions to the subproblems and merge them into a solution to the original problem.
Implementing into an algorithm:
- Divide: If has zero or one elements, return (as it is already sorted). Otherwise, remove all the elements from and put them into two sequences, and , each containing about half of the elements of S.
- Conquer: Recursively sort sequences of and .
- Combine: Put back the elements into by merging the sorted sequences and into a sorted sequence, i.e. elements of and elements of .
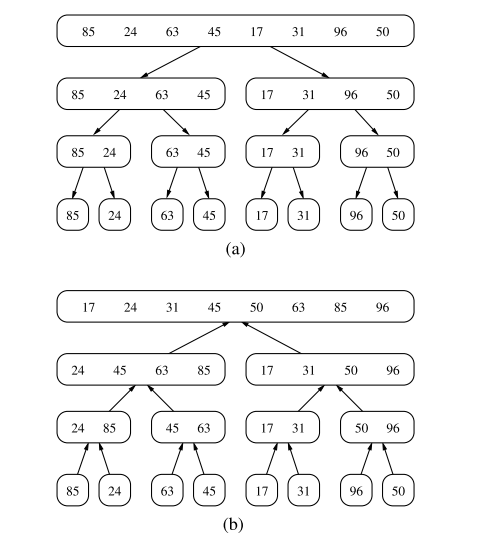
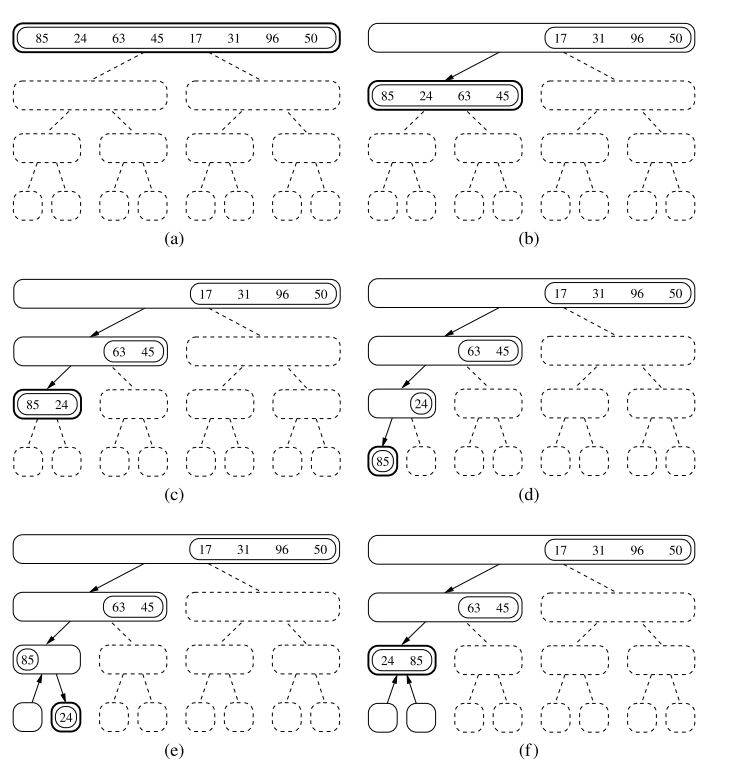
Each node of represents a recursive invocation of the merge-sort algorithm. We associate with each node of the sequence that is processed by the invocation associated with .
The algorithm visualisation in terms of the merge-sort tree helps us analyse the running time of the merge-sort algorithm. Each node of the tree represents a recursive call of merge-sort.
Implementation of Merge-Sort
- The
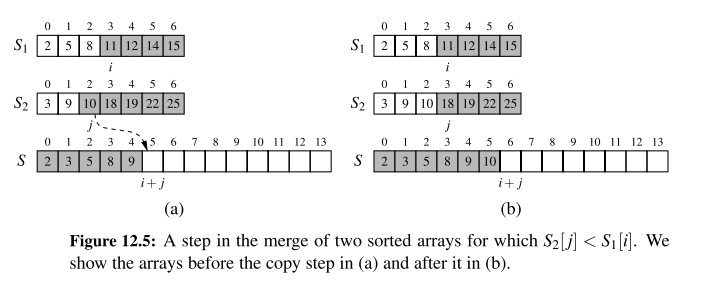
mergefunction is responsible for the subtask of merging two previously sorted sequences, and , with the output copied into .- We copy one element during each pass of the while loop, conditionally determining whether the next elements should be taken from or .
def merge(S1, S2, S):
"""Merge two sorted Python lists S1 and S2 into properly sized list S"""
i = j = 0
while i + j < len(S):
if j == len(S2) or (i < len(S1) and S1[i] < S2[j]):
S[i + j] = S1[i]
i += 1
else:
S[i + j] = S2[j]
j += 1
def merge_sort(S):
"""Sort the elements of Python list S using the merge-sort algorithm."""
n = len(S)
if n < 2:
return # list is already sorted
# divide
mid = n // 2
S1 = S[0:mid] # copy of first half
S2 = S[mid:n] # copy of second half
# conquer (with recursion)
merge_sort(S1) # sort copy of first half
merge_sort(S2) # sort copy of second half
# merge results
merge(S1, S2, S) # merge sorted halves back into S
A step of the merge process is illustrated in the following figure:
Running time of Merge-Sort
Let and be the number of elements of and , respectively. It is clear that the operations performed inside each pass of the while loop (of function merge) take time.
- During each iteration of the loop, one element is copied from either or into (and the element is considered no further). Therefore, the number of iterations of the loop is (and the time complexity would be ).
To determine the the complexity of the merge-sort algorithm, we account for the time to divide the sequence into two subsequences, and the call to merge to combine the two sorted sequences, but we exclude the two recursive calls to merge-sort.
Observations:
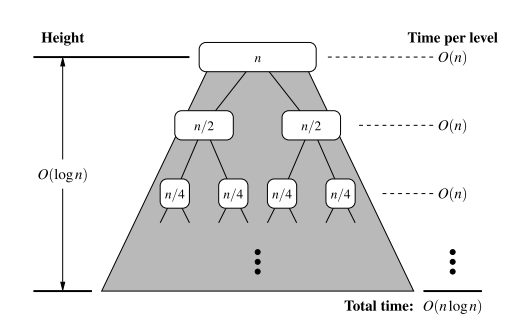
- The divide step at node runs in time proportional to the size of the sequence for
- The merging step also takes time that is linear in the size of the merged sequence.
- If we let denote the depth of node , the time spent at node is since the size of the sequence handled by the recursive called associated with is equal to
Given our definition of 'time spent at a node', the running time of merge-sort is equal to the sum of the times spent at the nodes of . Observe has exactly nodes at depth .
- The overall time spent at all the nodes of is , which is .
- The height of is Thus, the algorithm merge-sort sorts a sequence of size in times, assuming two elements can be compared in time.
Using recurrence equations to determine the time complexity of merge-sort
Let the function denote the worst-case running time of merge-sort on an input sequence of size n. We can characterise function by means of an equation where the function is recursively expressed in terms of itself.
In order to simplify the characterisation of , let us restrict our attention to the case when is a power of 2. Thus:
Observe that the function appears on the left and right hand sides of the equal sign, due to the design of the recurrence relation. However, we truly desire a Big-O characterisation of , i.e. a closed form characterisation of .
This can be obtained by applying the definition of a recurrence relation, assuming is relatively large.
If we apply the equation again, we get:
And applying the equation three times, obtain:
The issue remains, then, to determine when to stop this process. To see when to stop, recall that we switch to the closed for when , which will occur when . Thus,
Thus, we get an alternative justification of the fact that is .
Quick Sort
High level description of Quick-Sort:
The main idea is to apply a divide-and-conquer technique, and then combine the sorted subsequences by a simple concatenation.
- Divide: If S has at least two elements, select a specific elements from , which is called the pivot. As is common practise, choose the pivot to be the last element in . Remove all elements from and put them into three sequences
- , storing the elements in less than
- , storing the elements in equal to
- , storing the elements in greater than If the elements of are distinct, then only holds one element - the pivot itself.
- Conquer: Recursively sort sequences and
- Combine: Put back the elements into in order by first inserting the elements of , then those of , and finally those of .
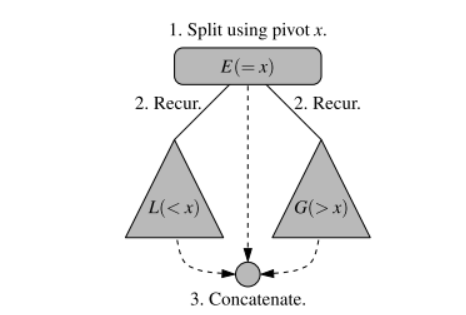
Unlike merge sort however, the height of the quick sort tree is linear in the worst case. This happens if the sequence consists of distinct elements and is already sorted.
Running time of quick sort
- The divide step and contanenation of of quick sort can be implemented in linear time
- We can bound the overall running time of the quick sort as , where is the height of the quicksort tree for that execution.
- The worst case of quick sort runs in time.
- The best case for quick-sort on a sequences occurs when subsequences and are roughly the same size. In that case, the tree has height and therefore would run in time.
- Introducing randomisation in the choice of a pivot makes quick-sort essentially behave in time on average.
Randomised quick sort
- Assume the pivot will always divide the sequences in a reaonsbly balanced manner.
- In general, we desire some way of getting close the the best-case running time for quick-sort
Picking pivots at random
- Pick as the pivot a random element of the input sequence. Instead of picking the pviot as the first or last element of , we pick an element of at random. This variation of quick-sortis called randomised quick-sort.
- The expected running time of a randomised quick-sort sequence is
Additional Optimisations for Quick sort
An algorithm is in-place if it uses only a small amount of memory in addition to that needed for the original input.
Our implementation of quick-sort does not qualify as in-place because we use additional containers , and when dividing a sequence within each recursive call.
Quick-sort of an array-based seuqence can be adapted to be in-place, and such an optimisation is used in most deployed implementations.
def inplace quick sort(S, a, b):
"""Sort the list from S[a] to S[b] inclusive using the quick-sort algorithm."""
if a >= b: return # range is trivially sorted
pivot = S[b] # last element of range is pivot
left = a # will scan rightward
right = b−1 # will scan leftward
while left <= right:
# scan until reaching value equal or larger than pivot (or right marker)
while left <= right and S[left] < pivot:
left += 1
# scan until reaching value equal or smaller than pivot (or left marker)
while left <= right and pivot < S[right]:
right −= 1
if left <= right: # scans did not strictly cross
S[left], S[right] = S[right], S[left] # swap values
left, right = left + 1, right − 1 # shrink range
# put pivot into its final place (currently marked by left index)
S[left], S[b] = S[b], S[left]
# make recursive calls
inplace quick sort(S, a, left − 1)
inplace quick sort(S, left + 1, b)
The in-place quick-sort modifies the input sequence using element swapping and does not explicitly create subsequences. Instead, the subsequence is implicitly represented by a range of positions specified by a leftmost and rightmost index and , respectively.
Although the implementation described in the section for dividing the sequence into two pieces is in-place, we note that the complete quick-sort algorithm needs space for a stack proportional to the depth of the recursion tree.
- Stack depth is . There is a trick that lets us guarantee the stack size is . Design a non-recursive function of in-place quick sort using an explicit stack to iteratively process subproblems. When pushing the new subproblems, we should first push the larger subproblem and then the smaller one. Then, the stack can have depth at most .