Module 4: Database design theory and Normalisation
Design Guidelines
Informal measures of relational database schema quality and design guidelines
- Making sure that the semantics of the attributes is clear in the schema.
- Reducing the redundant values in tuples.
- Reducing the null values in tuples.
- Disallowing the possibility of generating spurious tuples.
Formal Design guidelines
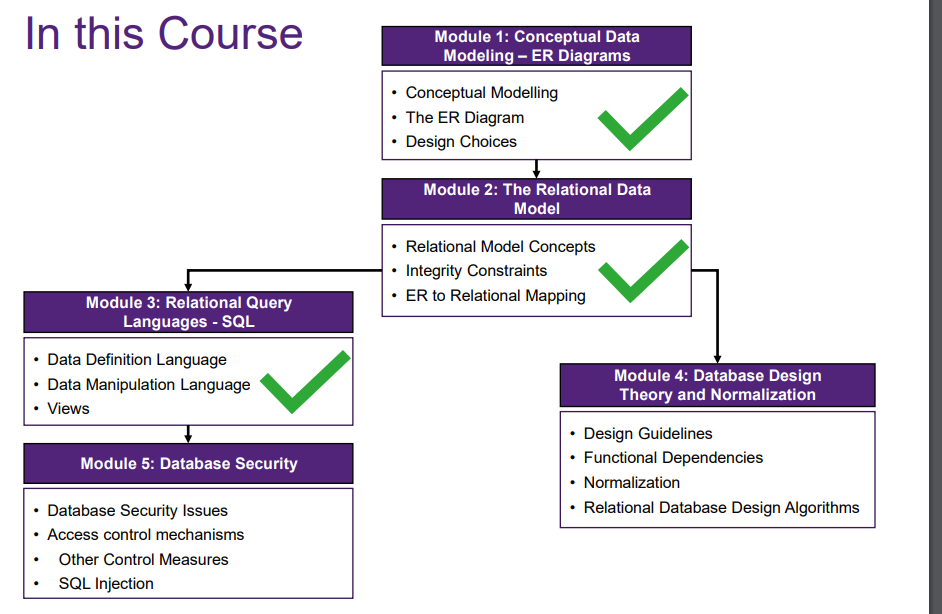
Guideline 1: Design each relation so that it is easy to explain its meaning
- Using meaningful names
- Do not combine attributes from multiple entity types and relationship types into a single relation
Redundant values in Tuples
- Design goal is to minimise the storage space that base relations occupy.
- In addition, an incorrect grouping may cause update anomalies which may result in inconsistent data or even loss of data.
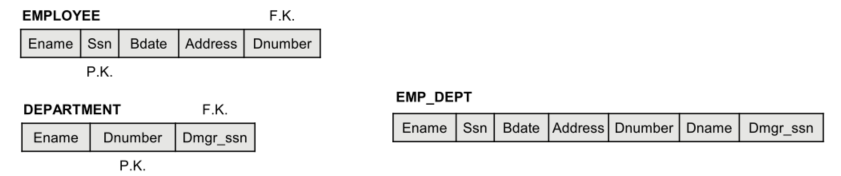
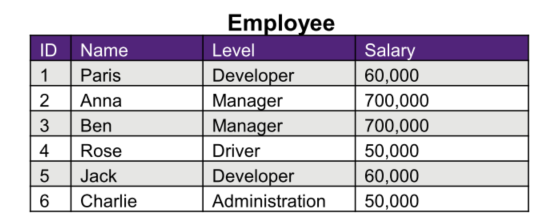
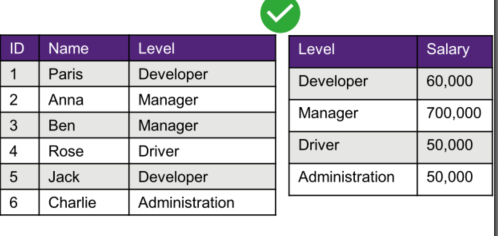
Example given in lectures
- A company where an employee’s salary directly corresponds to the level or position, they hold. For example, a manager has a fixed salary of $700,000 and a developer has a fixed salary of $60,000.
- I.e. The level of the employee implies the salary of the employee
Also:
level -> Salary
Modification Anomalies
- Updating the Salary of one developer, makes the “Developer” salary inconsistent.
Deletion Anomalies
- By deleting ”Charlie” we no longer store the salary of “Administration” Staff.
Insertion Anomalies
- We cannot store the salary of a “Cook” if no employee has that position.
- Inserting a new row with a different Salary for a developer, makes the “Developer” salary inconsistent.
Guideline 2: Design the base relation schema so that no insertion, deletion, or modification anomalies occur in the relations
- If any do occur, ensure that all applications that access the database update the relations in such a way as to not compromise the integrity of the database
Guideline 3: As far as possible, avoid placing attributes in a base relation whose values may be null
- Null values waste storage space, introduce ambiguity, and cannot be used for comparison
- If nulls are unavoidable, make sure that they apply in exceptional cases only in the relation
Decomposing and joining a relation
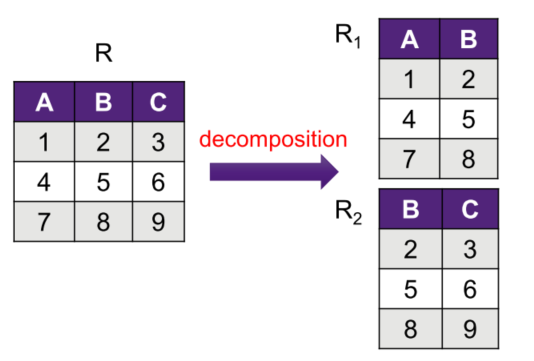
Decomposition
- A decomposition of R replaces R by two or more relations
such that:
- Each new relation contains a subset of the attributes of R (and no attributes not appearing in R)
- Every attribute of R appears in at least one new relation.
| Before | After |
|---|---|
 |
 |
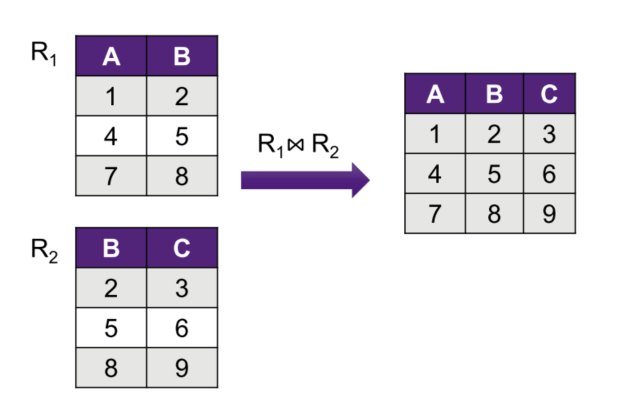
Join operation
Definition: is the natural join of the two relations
- Each tuple of R1 is concatenated with every tuple in R2 having the same values on the common attributes
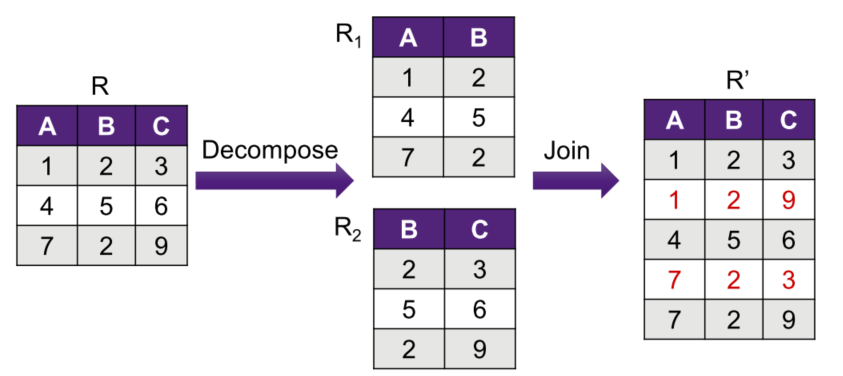
Lossy Join operation The word loss in lossless refers to loss of information, not loss of tuples
- Maybe a better term here is “addition of spurious information”
- Why is this a lossy join?
Functional dependencies
Databases allow you to say that one attribute determines another through a functional dependency
Formal Definition
A functional dependency (FD) holds on relation R if for every legal instance of such as , for all tuples t1, t2:
- Which means given two tuples in r, if their X values agree, then their Y values must also agree
- Example: level salary (i.e., if two employees have the same level, then they must have the same salary)
Keys
A key is a minimal set of attributes that uniquely identify a relation
- i.e., a key is a minimal set of attributes that functionally determines all the attributes in the relation A superkey for a relation uniquely identifies the relation
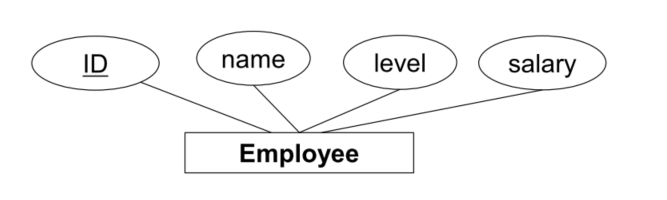
- Example key: {ID}
- Example superkey: {ID, level}
They have added the level to the field list - since it still uniquely identifies the relation, it is a superkey
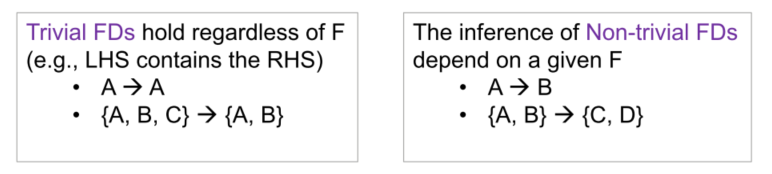
Implicit and Explicit FD's
Given a set of (explicit) functional dependencies, we can determine implicit ones
- Explicit FDs: ID level, level salary
- Implicit FD: ID salary
NOTE: this example above is called a transitive dependency, we will learn more about this next week!
Many implicit FDs can be derived
Closure of X (Finding Candidate Keys)
Closure of or is the set of attributes determined by X under F.

Will do will this to prove superkeys, or find candidate keys
A note about finding keys
Tips for finding keys:
- If an attribute does not appear on the RHS of any FDs in F, a key must contain that attribute
- e.g., D would be part of any key
- If a subset S is a key, there is no need to test any superset of S
- e.g., given {E, D} is key no need to check {E, D, A}
- One relation can have multiple keys of different length
- e.g., both {A, B, D} and {E, D} are keys
More on this in the tutorial